Working with semi-structured data in Snowflake provides great advantages, specially around the continuous ingestion approach. Let’s take a look at a simple way of having a single ingestion endpoint and splitting this data into multiple tables with one single insert while having the data at the ingestion level in a VARIANT data type. This approach could be combined with SnowPipe for automated ingestion and Streams to process only changes.
Let’s define a sample table with 1 Variant field. Also let’s add a Stream to this table to process only changes.
CREATE TABLE MULTI_SENSOR_INGEST
(
READING_DATA VARIANT
);
CREATE OR REPLACE STREAM STR_MULTI_SENSOR_INGEST
ON TABLE MULTI_SENSOR_INGEST
INSERT_ONLY = TRUE;
Now let’s define our 3 destination tables.
CREATE OR REPLACE TABLE PRESSURE_READINGS
(
READING_TIMESTAMP TIMESTAMP_TZ,
VALUE DECIMAL(4,0)
);
CREATE OR REPLACE TABLE TEMPERATURE_READINGS
(
READING_TIMESTAMP TIMESTAMP_TZ,
VALUE DECIMAL(4,0)
);
CREATE OR REPLACE TABLE HUMIDITY_READINGS
(
READING_TIMESTAMP TIMESTAMP_TZ,
VALUE DECIMAL(4,2)
);
Now for this sample, let’s generate 10k random records of sensors data for 3 sensor types, pressure, humidity and temperature. These sensor types will determine the destination tables to which data should be inserted. I am using the GENERATOR function along with OBJECT_CONSTRUCT to simulate data that might have come from SNOWPIPE.
INSERT INTO MULTI_SENSOR_INGEST
WITH GENERATED_DATA AS
(
SELECT DECODE(uniform(1,3,random()),
1,'temperature',
2,'pressure',
3, 'humidity') AS "sensor_type",
CASE WHEN "sensor_type" = 'temperature'
THEN object_construct('temperature', uniform(65,99,random())::decimal(4,0),
'timestamp', dateadd(millisecond,uniform(0,1000,random()),current_timestamp(2)))
WHEN "sensor_type" = 'pressure'
THEN object_construct('psi',uniform(135,200,random())::decimal(4,0),
'timestamp',dateadd(millisecond,uniform(0,1000,random()),current_timestamp(2)))
WHEN "sensor_type" = 'humidity'
THEN object_construct('hValue',uniform(25::float,99::float,random())::decimal(4,2),
'timestamp',dateadd(millisecond,uniform(0,1000,random()),current_timestamp(2)))
END AS "reading"
FROM TABLE(generator(rowcount=>10000))
) SELECT OBJECT_CONSTRUCT(*) as READING_DATA FROM GENERATED_DATA;
We can now process this data from the Stream created previously. Processing data from a stream, helps reduce latency by only processing data that has been inserted and has not been processed yet. Let’s take a look at the generated data with a sample of 10 rows.
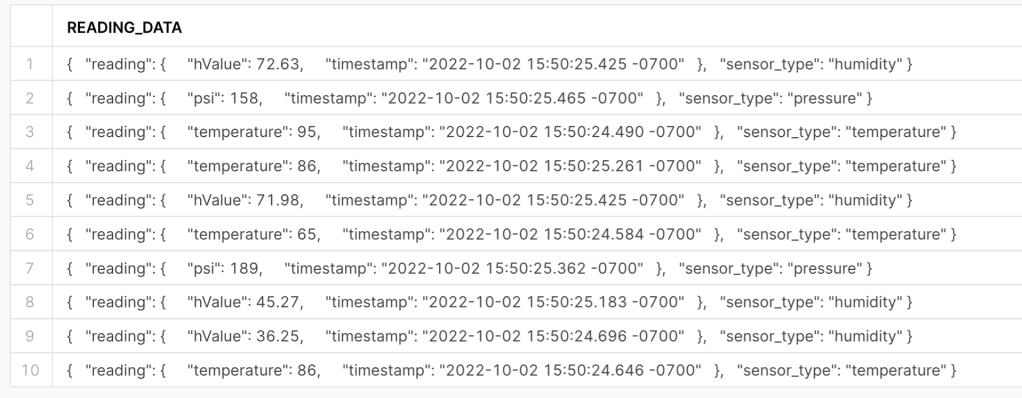
Processing Multi-Insert
The following script evaluates the SensorType field in the JSON object to determine the destination table for the insert. Having a single point of ingestion can be beneficial on certain occasions, specially when processing has been made to land aggregated multi-table data in one common location. Also this multi-table approach can be used to process inserts into multiple target based on mathematical conditions among others.
INSERT ALL
WHEN READING_DATA:sensor_type::VARCHAR = 'pressure'
THEN INTO PRESSURE_READINGS
(
READING_TIMESTAMP,
VALUE
)
VALUES
(
READING_DATA:reading:timestamp::TIMESTAMP_TZ,
READING_DATA:reading:psi::decimal(4,0)
)
WHEN READING_DATA:sensor_type::VARCHAR = 'temperature'
THEN INTO TEMPERATURE_READINGS
(
READING_TIMESTAMP,
VALUE
)
VALUES
(
READING_DATA:reading:timestamp::TIMESTAMP_TZ,
READING_DATA:reading:temperature::decimal(4,0)
)
WHEN READING_DATA:sensor_type::VARCHAR = 'humidity'
THEN INTO HUMIDITY_READINGS
(
READING_TIMESTAMP,
VALUE
)
VALUES
(
READING_DATA:reading:timestamp::TIMESTAMP_TZ,
READING_DATA:reading:humidity::decimal(4,2)
)
SELECT
READING_DATA
FROM
STR_MULTI_SENSOR_INGEST;
Now the results…

One of the benefits of Multi-table inserts is parallel processing. It will insert to multiple tables in a single operation which reduces the time needed to hold a transaction or the need to iterate through a list of tables to insert to. Look at the execution plan below. The insert node processed the records for 3 tables in a single step.
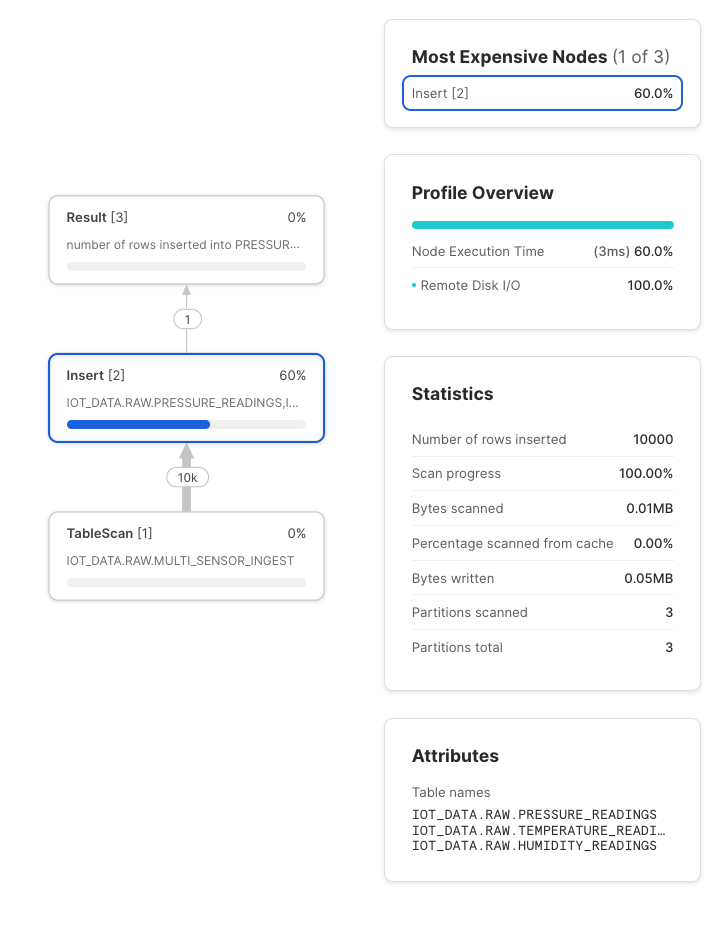
To summarize, Muti-Table inserts are a really neat alternative to process data for multiple destinations at once, specially data that has a single source and needs to be segregated. Combining this workflow with Snowflake options like SnowPipe and Streams can be a really powerful option. Enjoy!
